
The main strength of pgcopydb lies in its internal architecture. Unlike traditional PostgreSQL tools that often perform operations sequentially or with limited parallelism, pgcopydb was designed from the ground up to fully exploit modern multi-core CPUs and network capabilities.
In this article, we dissect the internal workings of pgcopydb and how it parallelizes database cloning.
A Robust Multi-Process Architecture
pgcopydb uses a multi-process architecture (via worker processes) orchestrated by a parent process. This approach ensures that a problem transferring one table does not block the entire migration.
The orchestrator follows a strict lifecycle to ensure data consistency:
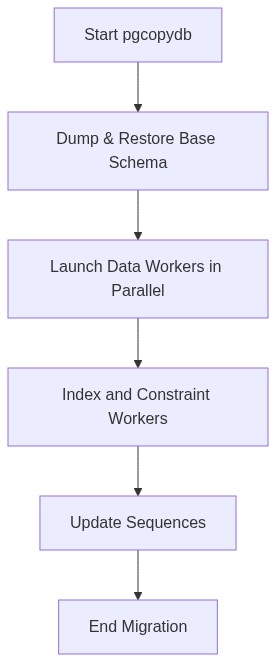
1. Pre-copy Phase: The Database Skeleton
Before injecting millions of rows, pgcopydb extracts the schema from the source database and applies it to the target. This step includes:
* Custom data types (Enums, Domains).
* Table structures (without indexes or foreign keys).
* PostgreSQL extensions.
By excluding indexes and foreign keys at this stage, pgcopydb ensures that inserting data in the next phase is not slowed down by index maintenance or integrity check constraints.
Ultra-Fast Data Copying
Once the structure is ready, the data copy phase begins. pgcopydb uses two parallelization mechanisms:
Inter-Table Parallelism
Multiple copy processes run simultaneously. By default, pgcopydb distributes tables among available workers. If you have 8 workers, 8 tables will be copied at the same time.
Intra-Table Parallelism (Table Chunking)
This is one of the tool’s most powerful features. For giant tables containing tens of millions of rows, a single-process copy would be a bottleneck.
pgcopydb can split a single table into multiple segments (or chunks) based on primary keys or unique numeric indexes. Each worker then copies its portion of the data in parallel using filtered queries, such as:
COPY (SELECT * FROM my_table WHERE id >= 1 AND id < 1000000) TO STDOUT;
Indexing and Constraints: Breaking the Bottleneck
In a classic migration, rebuilding indexes and applying foreign keys (FK) are often the longest steps. pgcopydb solves this brilliantly:
- Concurrent Index Creation: As soon as a worker finishes copying a specific table’s data, a message is sent to the orchestrator. The orchestrator immediately assigns index creation tasks for that table to free index workers. There is no need to wait for all tables to finish copying before starting index generation!
- Parallel Constraint Creation: Similarly, foreign key constraints are created in parallel as soon as both parent and child tables have been copied.
Why is This Approach Faster?
The table below summarizes the architectural differences between a classic approach and pgcopydb:
| Step | pg_dump / pg_restore Pipeline | pgcopydb |
|---|---|---|
| Dump/Extraction | Writing to disk or sequential streaming | Direct reading and parallel streaming |
| Data Copy | Often sequential per table | Multi-table and table partitioning (chunking) |
| Index Creation | Sequential at the end of the global restore | Parallel, as soon as an individual table is ready |
| Constraints (FK) | Applied sequentially at the end | Created in parallel as soon as possible |
This optimization allows pgcopydb to reduce migration times by a factor of 2x to over 5x, depending on database structure, network, and disk performance.
In the next article, we will see how to implement this parallelism in real-world scenarios with minimal downtime.
Official Resources
- GitHub Repository: dimitri/pgcopydb
- Official Documentation: pgcopydb Documentation