
L’atout majeur de pgcopydb réside dans son architecture interne. Contrairement aux outils traditionnels de PostgreSQL qui effectuent souvent des opérations de manière séquentielle ou avec un parallélisme limité, pgcopydb a été conçu dès le départ pour exploiter pleinement les processeurs multi-cœurs et les capacités réseau modernes.
Dans cet article, nous décortiquons le fonctionnement interne de pgcopydb et la façon dont il parallélise le clonage d’une base de données.
Une architecture multi-processus robuste
pgcopydb utilise une architecture multi-processus (via des processus de travail ou workers) orchestrée par un processus parent. Cette approche garantit qu’un problème sur le transfert d’une table ne bloque pas l’ensemble de la migration.
L’orchestrateur suit un cycle de vie strict pour garantir la cohérence des données :
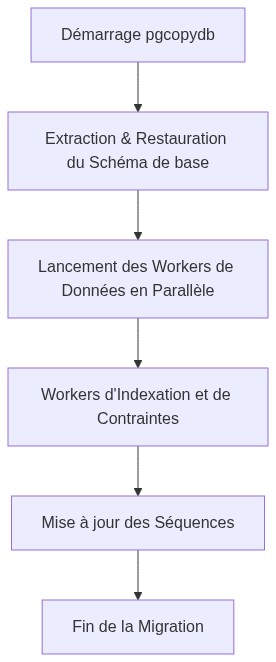
1. Phase de pré-copie : Le squelette de la base de données
Avant d’injecter des millions de lignes, pgcopydb extrait le schéma de la base source et l’applique sur la cible. Cette étape inclut :
* Les types de données personnalisés (Enums, Domaines).
* Les structures des tables (sans les index ni les clés étrangères).
* Les extensions PostgreSQL.
En excluant les index et les clés étrangères à ce stade, pgcopydb s’assure que l’insertion des données lors de la phase suivante ne sera pas ralentie par la maintenance des index ou les vérifications de contraintes d’intégrité référentielle.
La copie de données ultra-rapide
Une fois la structure prête, la phase de copie des données commence. pgcopydb utilise deux mécanismes de parallélisation :
Le parallélisme inter-tables
Plusieurs processus de copie s’exécutent simultanément. Par défaut, pgcopydb répartit les tables entre les workers disponibles. Si vous avez 8 workers, 8 tables seront copiées en même temps.
Le parallélisme intra-table (Table Chunking)
C’est l’une des fonctionnalités les plus puissantes de l’outil. Pour les tables géantes contenant des dizaines de millions de lignes, une copie mono-processus serait un goulot d’étranglement.
pgcopydb peut diviser une table unique en plusieurs segments (ou chunks) basés sur des clés primaires ou des index uniques (souvent des identifiants numériques). Chaque worker copie ensuite sa portion de données en parallèle via des requêtes filtrées, par exemple :
COPY (SELECT * FROM ma_table WHERE id >= 1 AND id < 1000000) TO STDOUT;
Indexation et contraintes : briser le goulot d’étranglement
Dans une migration classique, la reconstruction des index et l’application des clés étrangères (Foreign Keys) sont souvent les étapes les plus longues. pgcopydb résout ce problème avec brio :
- Création concurrente d’index : Dès qu’un worker termine la copie des données d’une table spécifique, un message est envoyé à l’orchestrateur. Celui-ci attribue immédiatement des tâches de création d’index pour cette table aux workers d’indexation libres. Il n’est pas nécessaire d’attendre la copie de toutes les tables de la base pour commencer à indexer !
- Création en parallèle de contraintes : De la même manière, les contraintes de clés étrangères sont créées en parallèle dès que les tables parentes et enfants ont été copiées.
Pourquoi cette approche est-elle plus rapide ?
Le tableau ci-dessous résume les différences architecturales entre une approche classique et pgcopydb :
| Étape | Pipeline pg_dump / pg_restore | pgcopydb |
|---|---|---|
| Extraction | Écriture sur disque ou streaming séquentiel | Lecture directe et streaming en parallèle |
| Copie des données | Souvent séquentielle par table | Multi-tables et découpage (chunking) de tables |
| Création d’index | Séquentielle à la fin de la restauration globale | Parallèle, dès qu’une table individuelle est prête |
| Contraintes (FK) | Appliquées séquentiellement à la fin | Créées en parallèle dès que possible |
Cette optimisation permet à pgcopydb de diviser les temps de migration par un facteur allant de 2x à plus de 5x selon la structure de la base de données et les performances E/S réseau et disque.
Dans l’article suivant, nous verrons comment mettre en œuvre ce parallélisme dans des scénarios réels avec un temps d’arrêt minimal.
Ressources Officielles
- Dépôt GitHub : dimitri/pgcopydb
- Documentation Officielle : Documentation pgcopydb